A CPU core is a scarce resource in high demand from all the different process running on a computer machine. When you are choosing how to allocate your nodes to available CPU cores, CoralSequencer gives you the option to run several nodes inside the same NioReactor thread, which in turn will be pinned to an isolated CPU core. As the number of nodes inside the same CPU core grows, fan-out might become an issue affecting latency, as now the thread has to cycle through all nodes as it reads multicast messages from the event-stream. In this article we explain (with diagrams) how you can deal with that scenario by choosing CoralSequencer’s shared-memory transport instead of multicast at the node machine level.
Multicast Fan-Out
So let’s say you have 20 nodes running on the same thread. After Node 1 reads its multicast message, it will have to wait for all other 19 nodes to read the multicast message before it can proceed to read the next message. The network card receiving the multicast message has to make 20 copies of the message, placing each copy in the individual underlying native receive socket buffer of each node. The diagram below illustrates this scenario:
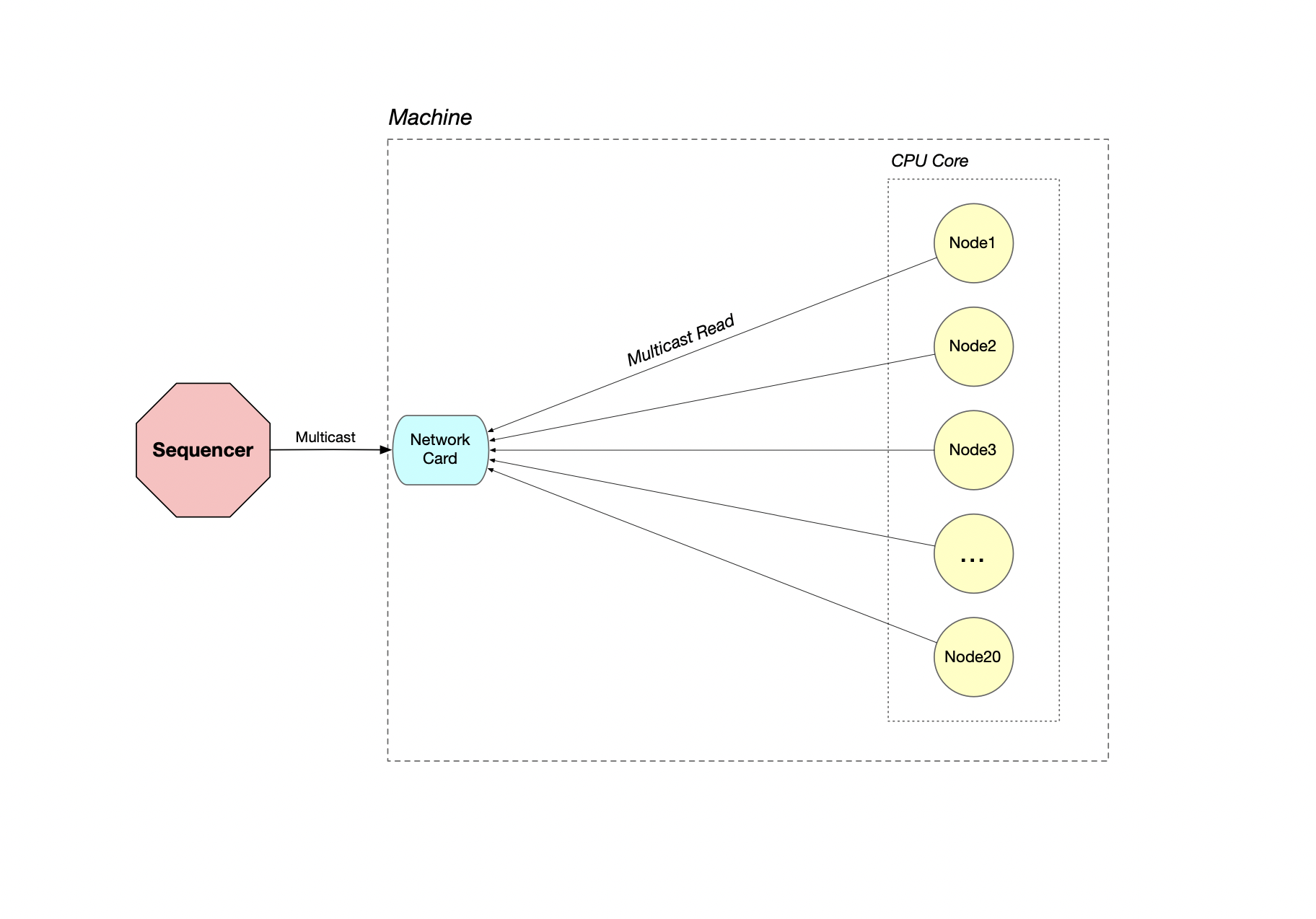
So that begs the question: How will an individual node latency be affected as we keep adding more nodes to its thread? Below the results of the benchmark tests:
1 Node: (baseline or zero fan-out) 20:00:56.170513-INFO NODE1 Finished latency test! msgSize=16 results=Iterations: 1,000,000 | Avg Time: 4.503 micros | Min Time: 3.918 micros | Max Time: 704.095 micros | 75% = [avg: 4.272 micros, max: 4.69 micros] | 90% = [avg: 4.35 micros, max: 4.799 micros] | 99% = [avg: 4.41 micros, max: 5.783 micros] | 99.9% = [avg: 4.425 micros, max: 7.037 micros] | 99.99% = [avg: 4.468 micros, max: 264.298 micros] | 99.999% = [avg: 4.497 micros, max: 436.127 micros] 2 Nodes: 20:22:48.562317-INFO NODE1 Finished latency test! msgSize=16 results=Iterations: 1,000,000 | Avg Time: 4.556 micros | Min Time: 3.983 micros | Max Time: 650.027 micros | 75% = [avg: 4.227 micros, max: 4.696 micros] | 90% = [avg: 4.38 micros, max: 5.213 micros] | 99% = [avg: 4.462 micros, max: 5.706 micros] | 99.9% = [avg: 4.478 micros, max: 6.871 micros] | 99.99% = [avg: 4.519 micros, max: 274.402 micros] | 99.999% = [avg: 4.55 micros, max: 490.207 micros] 3 Nodes: 20:21:33.572903-INFO NODE1 Finished latency test! msgSize=16 results=Iterations: 1,000,000 | Avg Time: 5.614 micros | Min Time: 3.943 micros | Max Time: 691.881 micros | 75% = [avg: 5.224 micros, max: 5.954 micros] | 90% = [avg: 5.355 micros, max: 6.098 micros] | 99% = [avg: 5.503 micros, max: 7.64 micros] | 99.9% = [avg: 5.527 micros, max: 9.422 micros] | 99.99% = [avg: 5.582 micros, max: 253.727 micros] | 99.999% = [avg: 5.608 micros, max: 398.772 micros] 4 Nodes: 20:20:08.231927-INFO NODE1 Finished latency test! msgSize=16 results=Iterations: 1,000,000 | Avg Time: 6.728 micros | Min Time: 4.555 micros | Max Time: 464.322 micros | 75% = [avg: 6.562 micros, max: 6.681 micros] | 90% = [avg: 6.587 micros, max: 6.76 micros] | 99% = [avg: 6.619 micros, max: 7.348 micros] | 99.9% = [avg: 6.631 micros, max: 9.444 micros] | 99.99% = [avg: 6.702 micros, max: 208.45 micros] | 99.999% = [avg: 6.724 micros, max: 331.632 micros] 5 Nodes: 20:04:31.776798-INFO NODE1 Finished latency test! msgSize=16 results=Iterations: 1,000,000 | Avg Time: 7.982 micros | Min Time: 5.433 micros | Max Time: 364.291 micros | 75% = [avg: 7.667 micros, max: 8.355 micros] | 90% = [avg: 7.795 micros, max: 8.509 micros] | 99% = [avg: 7.872 micros, max: 9.093 micros] | 99.9% = [avg: 7.886 micros, max: 11.372 micros] | 99.99% = [avg: 7.959 micros, max: 190.152 micros] | 99.999% = [avg: 7.978 micros, max: 278.21 micros] 10 Nodes: 20:10:03.527401-INFO NODE1 Finished latency test! msgSize=16 results=Iterations: 1,000,000 | Avg Time: 13.555 micros | Min Time: 7.098 micros | Max Time: 266.888 micros | 75% = [avg: 12.773 micros, max: 15.157 micros] | 90% = [avg: 13.201 micros, max: 15.634 micros] | 99% = [avg: 13.436 micros, max: 16.061 micros] | 99.9% = [avg: 13.475 micros, max: 58.272 micros] | 99.99% = [avg: 13.539 micros, max: 132.831 micros] | 99.999% = [avg: 13.552 micros, max: 189.882 micros] 15 Nodes: 20:14:16.156609-INFO NODE1 Finished latency test! msgSize=16 results=Iterations: 1,000,000 | Avg Time: 16.647 micros | Min Time: 11.668 micros | Max Time: 189.303 micros | 75% = [avg: 15.769 micros, max: 17.76 micros] | 90% = [avg: 16.205 micros, max: 19.094 micros] | 99% = [avg: 16.522 micros, max: 20.563 micros] | 99.9% = [avg: 16.58 micros, max: 55.764 micros] | 99.99% = [avg: 16.636 micros, max: 107.489 micros] | 99.999% = [avg: 16.645 micros, max: 143.581 micros] 20 Nodes: 20:18:00.346389-INFO NODE1 Finished latency test! msgSize=16 results=Iterations: 1,000,000 | Avg Time: 21.842 micros | Min Time: 13.524 micros | Max Time: 170.239 micros | 75% = [avg: 20.484 micros, max: 24.261 micros] | 90% = [avg: 21.237 micros, max: 25.691 micros] | 99% = [avg: 21.711 micros, max: 27.423 micros] | 99.9% = [avg: 21.788 micros, max: 59.232 micros] | 99.99% = [avg: 21.832 micros, max: 92.211 micros] | 99.999% = [avg: 21.84 micros, max: 132.365 micros]
Shared Memory Fan-Out through the Dispatcher node
When you use CoralSequencer’s Dispatcher node, only the dispatcher node will read the multicast messages from the network card. It will proceed to write the messages to shared memory. Then any other node running on that machine can choose to read the messages from the same shared memory (from the dispatcher) instead of multicast (from the network card). The diagram below illustrates this scenario:
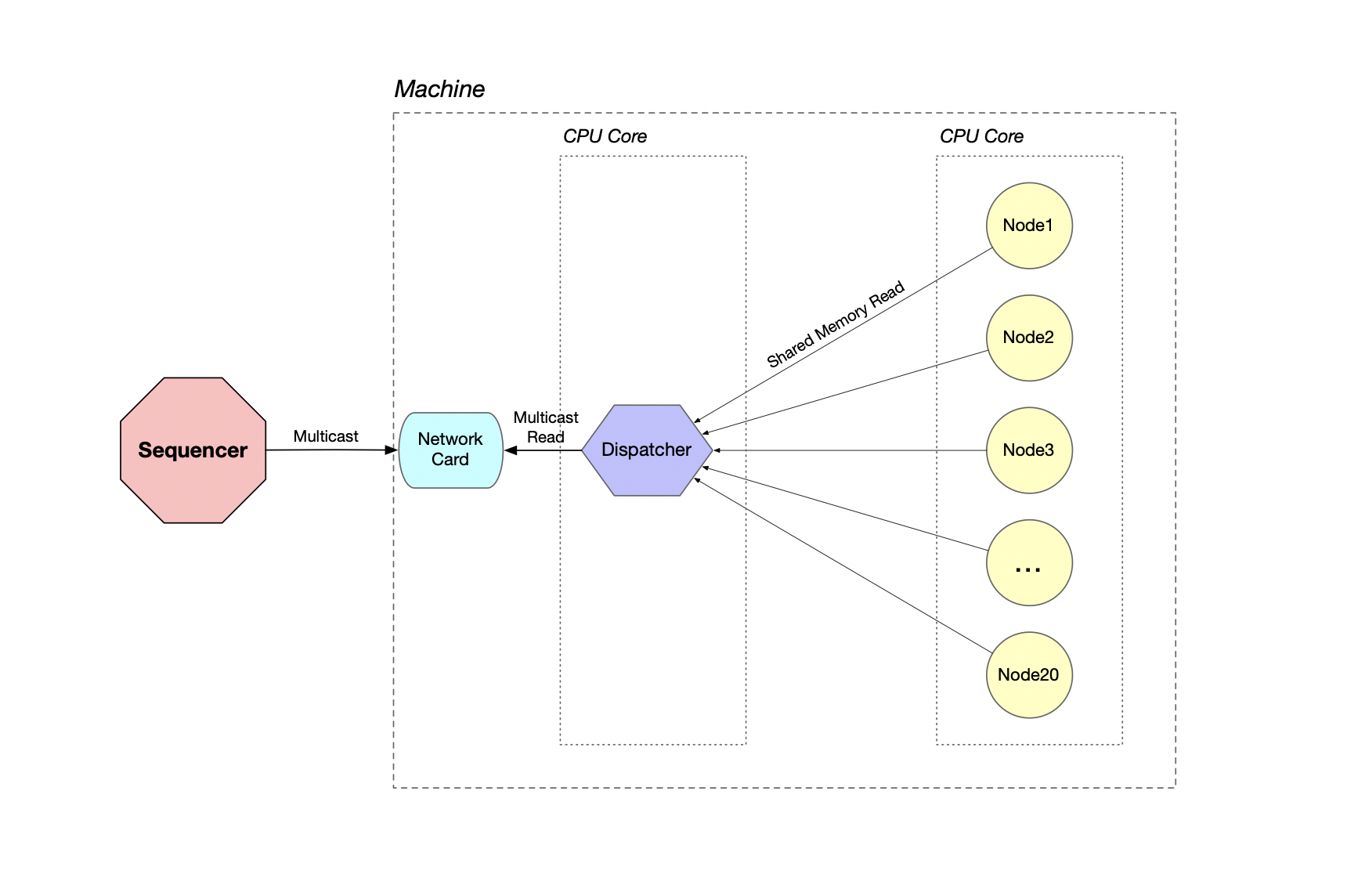
Is reading from shared memory any faster than reading from the network, even when we are using non-blocking networks reads? Let’s repeat the same benchmark tests to find out:
1 Node: (baseline or zero fan-out) 06:28:56.524909-INFO NODE1 Finished latency test! msgSize=16 results=Iterations: 1,000,000 | Avg Time: 5.136 micros | Min Time: 4.173 micros | Max Time: 594.837 micros | 75% = [avg: 4.903 micros, max: 5.171 micros] | 90% = [avg: 4.954 micros, max: 5.46 micros] | 99% = [avg: 5.021 micros, max: 6.042 micros] | 99.9% = [avg: 5.034 micros, max: 7.875 micros] | 99.99% = [avg: 5.102 micros, max: 268.368 micros] | 99.999% = [avg: 5.131 micros, max: 419.933 micros] 2 Nodes: 06:30:40.480024-INFO NODE1 Finished latency test! msgSize=16 results=Iterations: 1,000,000 | Avg Time: 5.42 micros | Min Time: 4.246 micros | Max Time: 581.791 micros | 75% = [avg: 5.156 micros, max: 5.591 micros] | 90% = [avg: 5.239 micros, max: 5.754 micros] | 99% = [avg: 5.303 micros, max: 6.321 micros] | 99.9% = [avg: 5.316 micros, max: 7.977 micros] | 99.99% = [avg: 5.385 micros, max: 292.002 micros] | 99.999% = [avg: 5.415 micros, max: 459.128 micros] 3 Nodes: 06:32:19.770820-INFO NODE1 Finished latency test! msgSize=16 results=Iterations: 1,000,000 | Avg Time: 5.649 micros | Min Time: 4.174 micros | Max Time: 1.023 millis | 75% = [avg: 5.366 micros, max: 5.793 micros] | 90% = [avg: 5.457 micros, max: 6.059 micros] | 99% = [avg: 5.527 micros, max: 6.491 micros] | 99.9% = [avg: 5.54 micros, max: 8.244 micros] | 99.99% = [avg: 5.614 micros, max: 282.519 micros] | 99.999% = [avg: 5.643 micros, max: 453.64 micros] 4 Nodes: 06:35:39.689059-INFO NODE1 Finished latency test! msgSize=16 results=Iterations: 1,000,000 | Avg Time: 5.77 micros | Min Time: 4.26 micros | Max Time: 645.956 micros | 75% = [avg: 5.479 micros, max: 5.948 micros] | 90% = [avg: 5.577 micros, max: 6.195 micros] | 99% = [avg: 5.65 micros, max: 6.781 micros] | 99.9% = [avg: 5.664 micros, max: 8.362 micros] | 99.99% = [avg: 5.736 micros, max: 264.038 micros] | 99.999% = [avg: 5.764 micros, max: 437.225 micros] 5 Nodes: 06:40:42.531026-INFO NODE1 Finished latency test! msgSize=16 results=Iterations: 1,000,000 | Avg Time: 6.291 micros | Min Time: 4.361 micros | Max Time: 753.637 micros | 75% = [avg: 5.929 micros, max: 6.636 micros] | 90% = [avg: 6.068 micros, max: 6.912 micros] | 99% = [avg: 6.164 micros, max: 7.488 micros] | 99.9% = [avg: 6.18 micros, max: 9.14 micros] | 99.99% = [avg: 6.256 micros, max: 272.228 micros] | 99.999% = [avg: 6.285 micros, max: 451.461 micros] 10 Nodes: 06:44:12.332180-INFO NODE1 Finished latency test! msgSize=16 results=Iterations: 1,000,000 | Avg Time: 6.722 micros | Min Time: 4.478 micros | Max Time: 509.009 micros | 75% = [avg: 6.245 micros, max: 7.258 micros] | 90% = [avg: 6.455 micros, max: 7.787 micros] | 99% = [avg: 6.599 micros, max: 8.502 micros] | 99.9% = [avg: 6.618 micros, max: 10.021 micros] | 99.99% = [avg: 6.693 micros, max: 235.364 micros] | 99.999% = [avg: 6.718 micros, max: 370.217 micros] 15 Nodes: 06:48:31.743422-INFO NODE1 Finished latency test! msgSize=16 results=Iterations: 1,000,000 | Avg Time: 7.531 micros | Min Time: 4.759 micros | Max Time: 499.443 micros | 75% = [avg: 7.028 micros, max: 7.884 micros] | 90% = [avg: 7.202 micros, max: 8.31 micros] | 99% = [avg: 7.373 micros, max: 10.167 micros] | 99.9% = [avg: 7.402 micros, max: 12.745 micros] | 99.99% = [avg: 7.499 micros, max: 251.521 micros] | 99.999% = [avg: 7.526 micros, max: 403.692 micros] 20 Nodes: 06:53:27.062402-INFO NODE1 Finished latency test! msgSize=16 results=Iterations: 1,000,000 | Avg Time: 9.506 micros | Min Time: 4.866 micros | Max Time: 438.516 micros | 75% = [avg: 9.003 micros, max: 10.057 micros] | 90% = [avg: 9.213 micros, max: 10.482 micros] | 99% = [avg: 9.356 micros, max: 11.654 micros] | 99.9% = [avg: 9.381 micros, max: 17.448 micros] | 99.99% = [avg: 9.479 micros, max: 217.556 micros] | 99.999% = [avg: 9.502 micros, max: 348.865 micros]
Graph Comparison
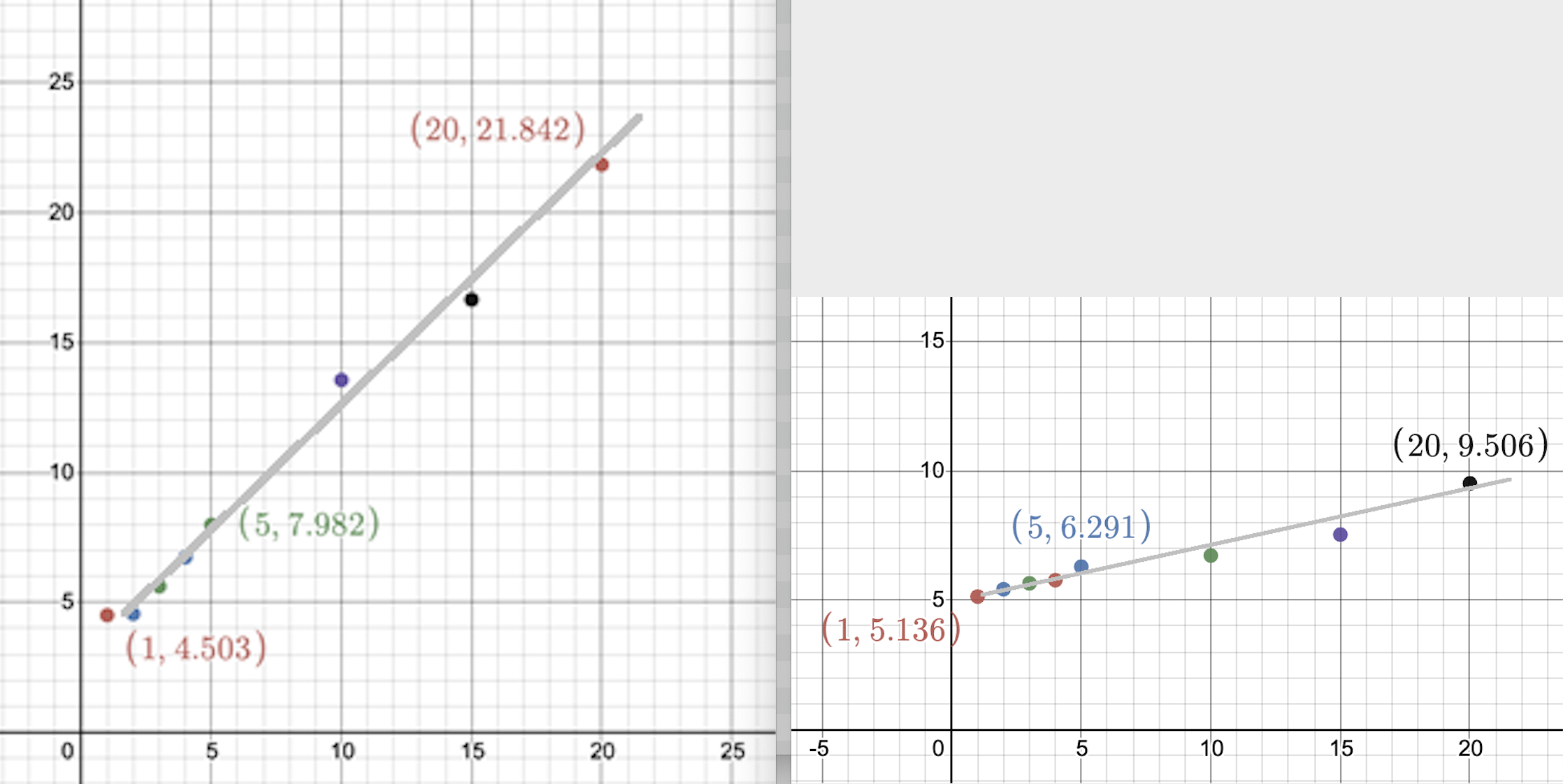
FAQ:
- Does the dispatcher use a circular buffer as shared memory?
Yes, and because it is shared-memory through a memory-mapped file, it can be made as large as your disk space can handle. Furthermore, the circular buffer provides safety guards so that a consumer is not reading a message that is currently being written by the producer. - Do the nodes read from the same shared-memory space?
Yes, the dispatcher writes once to the shared-memory space. All nodes read from this same shared-memory space. - Can nodes in different threads/JVMs be reading from the same dispatcher at the same time?
Yes, the dispatcher can handle multiple threads consuming the same messages concurrently. They do not need to be in the same thread as they are in this example. The reason they are placed in the same thread in this example is to illustrate and address the fan-out issue. If they are reading from multiple threads then the fan-out issue goes away. But you would still have gains by removing the load from the network card so that it does not have to copy the same message to multiple underlying socket buffers. With the dispatcher, the network card copies the messages only once to the shared-memory store and all the nodes read the messages from that same shared-memory store.
Conclusion
Adding a shared-memory dispatcher improves latency in fan-out scenarios, when for some reason you need/want to run several nodes inside the same NioReactor thread (i.e. inside the same CPU core). The dispatcher takes the load off the network card as now the network card has to deliver the message only once (to the dispatcher) instead of 20 times (to each of the 20 nodes).