In this article we will explore an architecture employed by some of the most sophisticated electronic exchanges, the ones that need to handle millions of orders per day with ultra-low-latency and high-availability. Most of the exchange main architecture components will be presented as CoralSequencer nodes and discussed through diagrams. The goal of this article is to demonstrate how a total-ordered messaging middleware such as CoralSequencer naturally enables the implementation and control of complex distributed system through a tight integration of all its moving parts. This article doesn’t mention specifics about any exchange’s internal systems and instead talks about the big picture and the general concepts, which will vary from exchange to exchange.
TCP Order Port
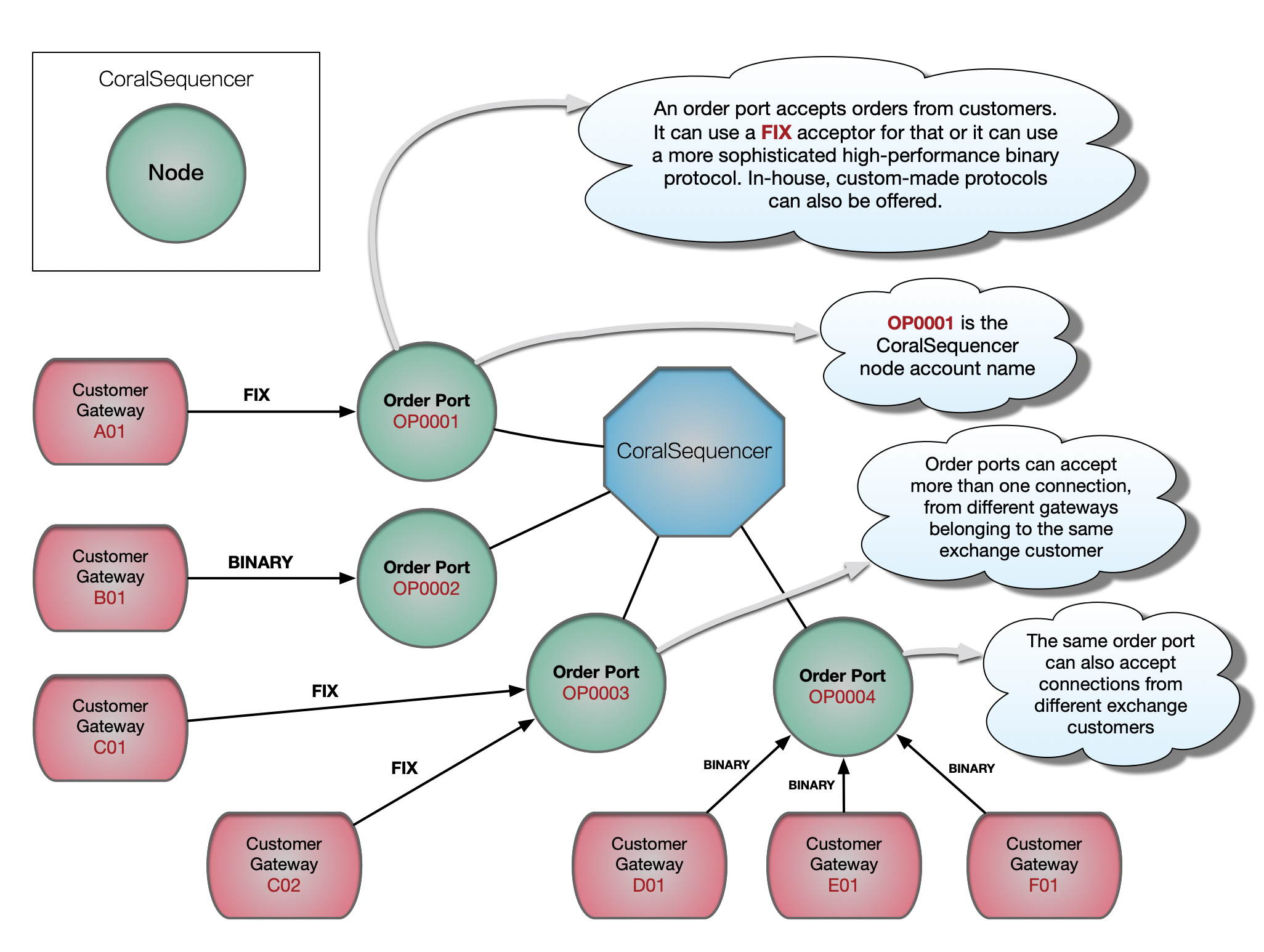
Although it is technically possible to run more than one Order Port server inside the same node, each node will usually run a single Order Port server (FIX, BINARY or XXXX) capable of accepting several gateway connections from customers. The same JVM can be configured to run several nodes, each node running an Order Port server, each server listening to incoming gateway connections on its own network port. And all that is run by a single critical high-performance thread, pinned to an isolated CPU core. When we say single-thread, we actually mean it. The handling of the messaging middleware (sending and receiving messages to and from CoralSequencer) is also done by this same critical thread, through non-blocking network I/O operations.
Order Port High-Availability and Failover
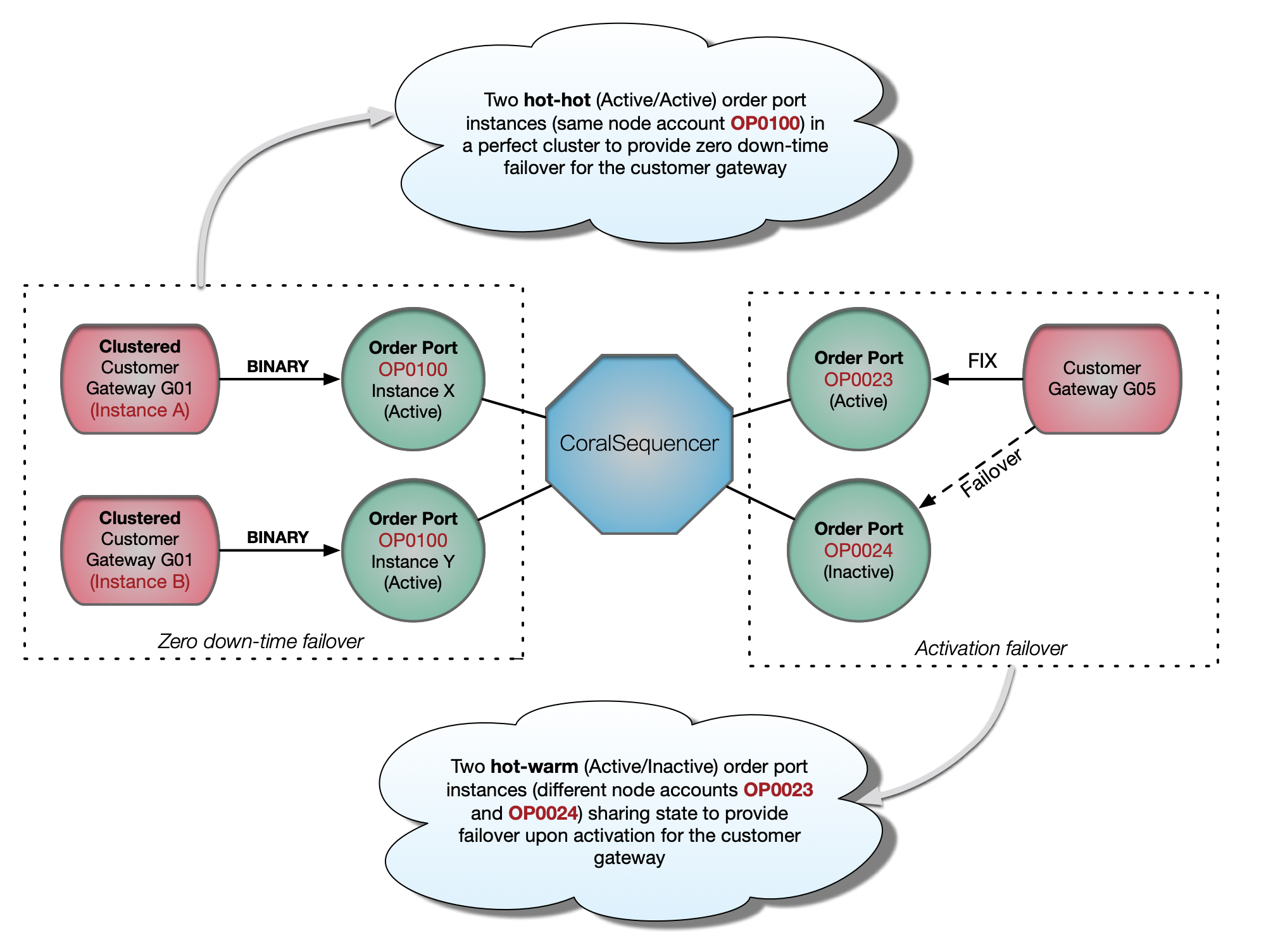
With hot-hot failover, the customer can literally pull the plug from one of his clustered gateway machines, for a zero-downtime failover. Note that the same is true on the exchange side: the exchange can pull the plug from any Order Port instance for a zero-downtime failover.
With hot-warm failover, there is a small down-time as the backup Order Port node needs to be activated (manually or automatically) and the customer gateway needs to connect to the new machine, either though a virtual IP change on the exchange side or through a destination IP change on the customer side.
Matching Engine
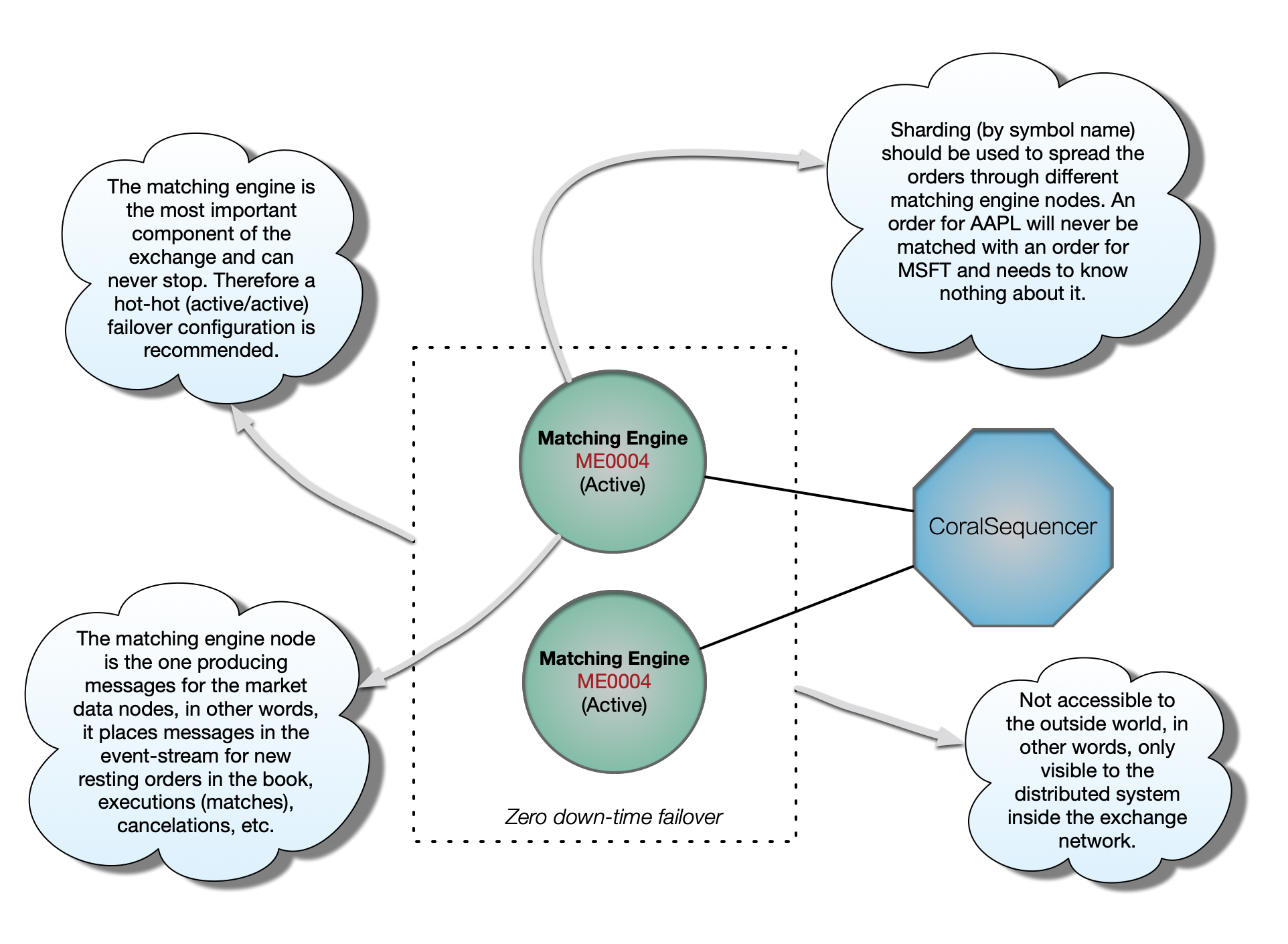
The matching engine is the brain of the exchange, where buy orders are matching sell orders (and vice-versa). It builds and maintains a double-sided (bids and asks) liquidity order book for each symbol, and matches incoming orders accordingly.
The matching engine is critical (i.e. can never stop) and needs to be as fast as possible (i.e. can never block) as all other exchange components depend on it.
Instead of using one matching engine for all symbols, it makes a lot of sense to use a sharding strategy to spread the load across several matching engines. For example, an exchange may choose to have one matching engine for symbol names beginning with A-G, another one for H-N and another one for O-Z. Of course a good sharding strategy will depend on how active each symbol is so that to spread the load as evenly as possible.
TCP Market Data
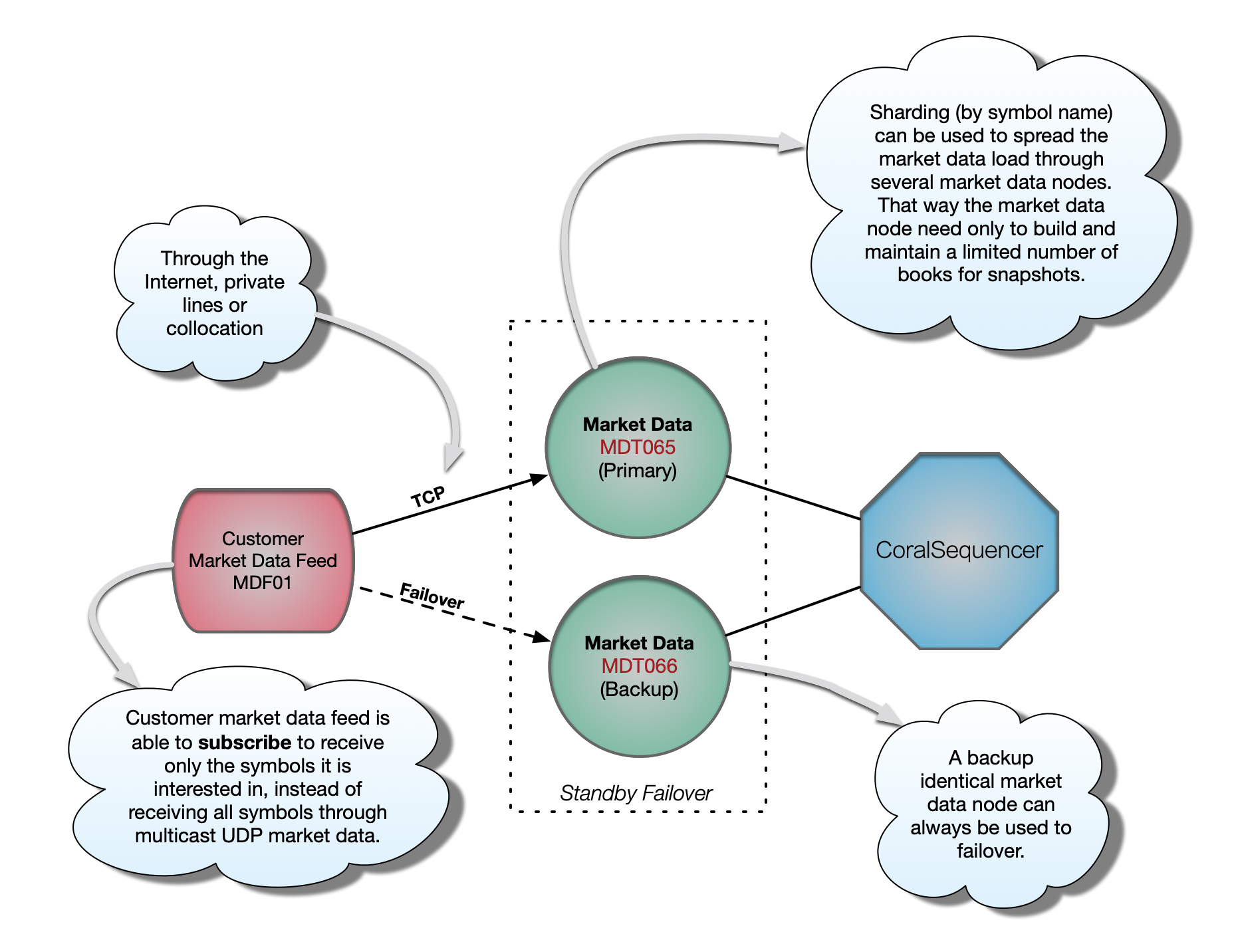
TCP market data is slower but has some advantages over Multicast UDP market data. First the customer market data feed can subscribe to receive only the symbols it is interested in. With Multicast UDP market data, all symbols are pushed to the customer. Not the entire number of symbols from the exchange, but all symbols present in that Multicast UDP channel as defined by the sharding strategy. Second, upon subscription, the customer usually receives a snapshot of the entire market data book. With Multicast UDP only incremental updates are sent, never snapshots. And third, because the customer can identify himself over the TCP connection, it is usually easy for the exchange to flag the market data orders belonging to that customer. That’s useful information that the exchange customer can use to prevent trading to himself, which a compliant exchange might choose to disallow through order rejects.
Multicast UDP Market Data
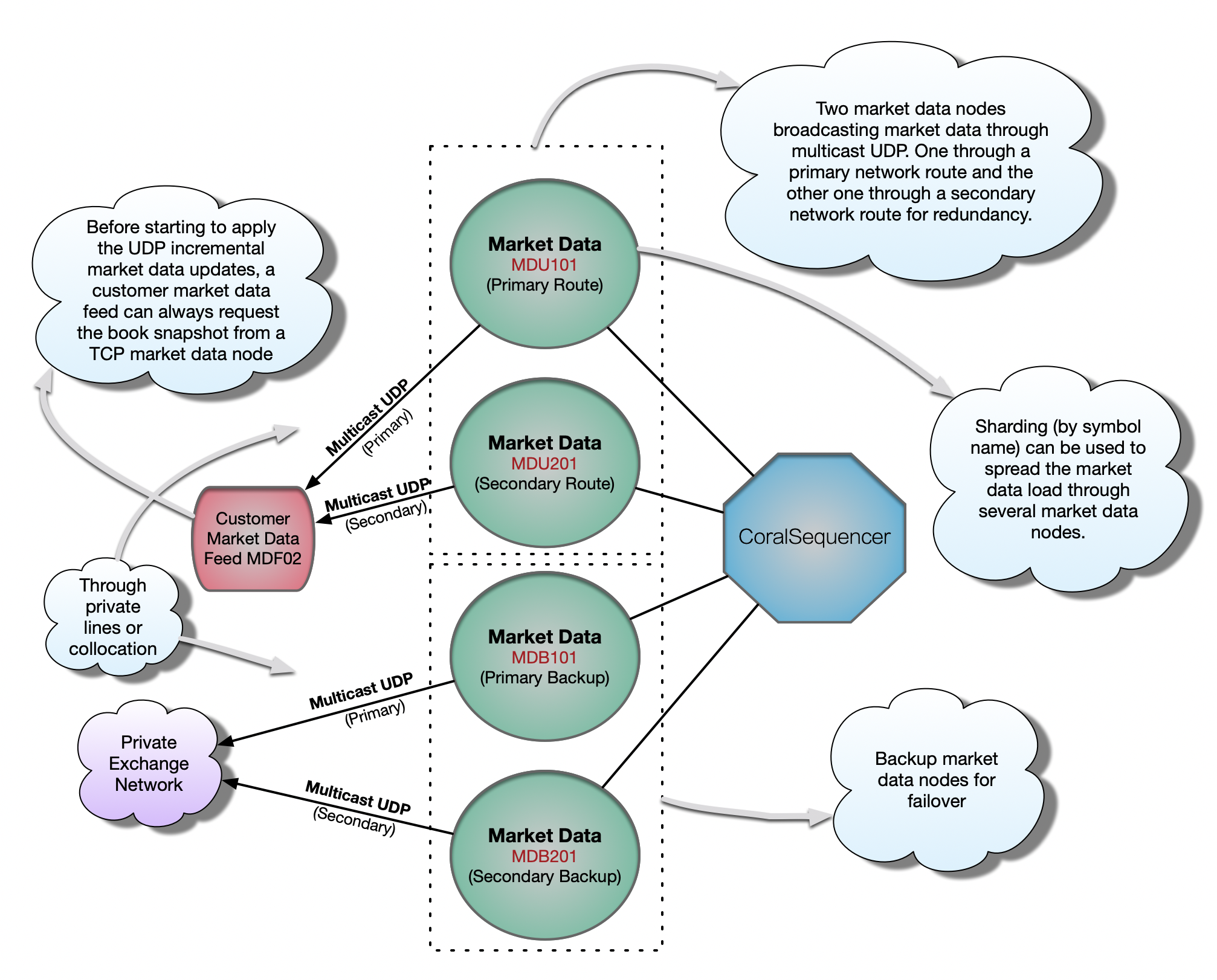
An exchange can (and will) have thousands of customers interested in connectivity for market data. Maintaining a TCP market data channel for each one of them can quickly become impractical. The solution is to push out market data through multicast UDP to whoever wants to listen. That’s usually done by private network lines and collocation, never though the Internet due to the unreliability of UDP and because multicast is not supported over the public Internet.
It is important to notice that a multicast udp market data node will only broadcast incremental market data updates, never book snapshots. Therefore, some special logic needs to be implemented on the customer side to: first listen to the multicast UDP market data channel; buffer the initial incremental update messages; make a request for the initial market data book (i.e. snapshot) from a TCP market data channel; close the TCP connection; apply the buffered messages; then start applying the live incremental updates from the UDP channel.
Because of the unreliability nature of UDP, the exchange will usually multicast the market data over two redundant channels. The customer market data feed will listen to both at the same time and consume the packet that arrives first, discarding the slower duplicate. That minimizes the chances of gaps in the line (i.e. lost packets), as losing the same packet on both lines becomes less likely but still possible. Some exchanges will provide retransmission servers, specially for those customers that want/need to have all incremental updates for historical reference. If a retransmission server is not provided and/or the customer does not want to go through the trouble of implementing the retransmission request logic, the customer market data feed can just start from scratch by requesting a new book snapshot after a packet loss.
Last but not least, the customer can use the order id present in the market data incremental updates and check against its open orders to find out whether that order is his or not. As already said, that’s useful information that the exchange customer can use to prevent illegal trades-to-self.
TCP Drop Copy ( position, position, position )
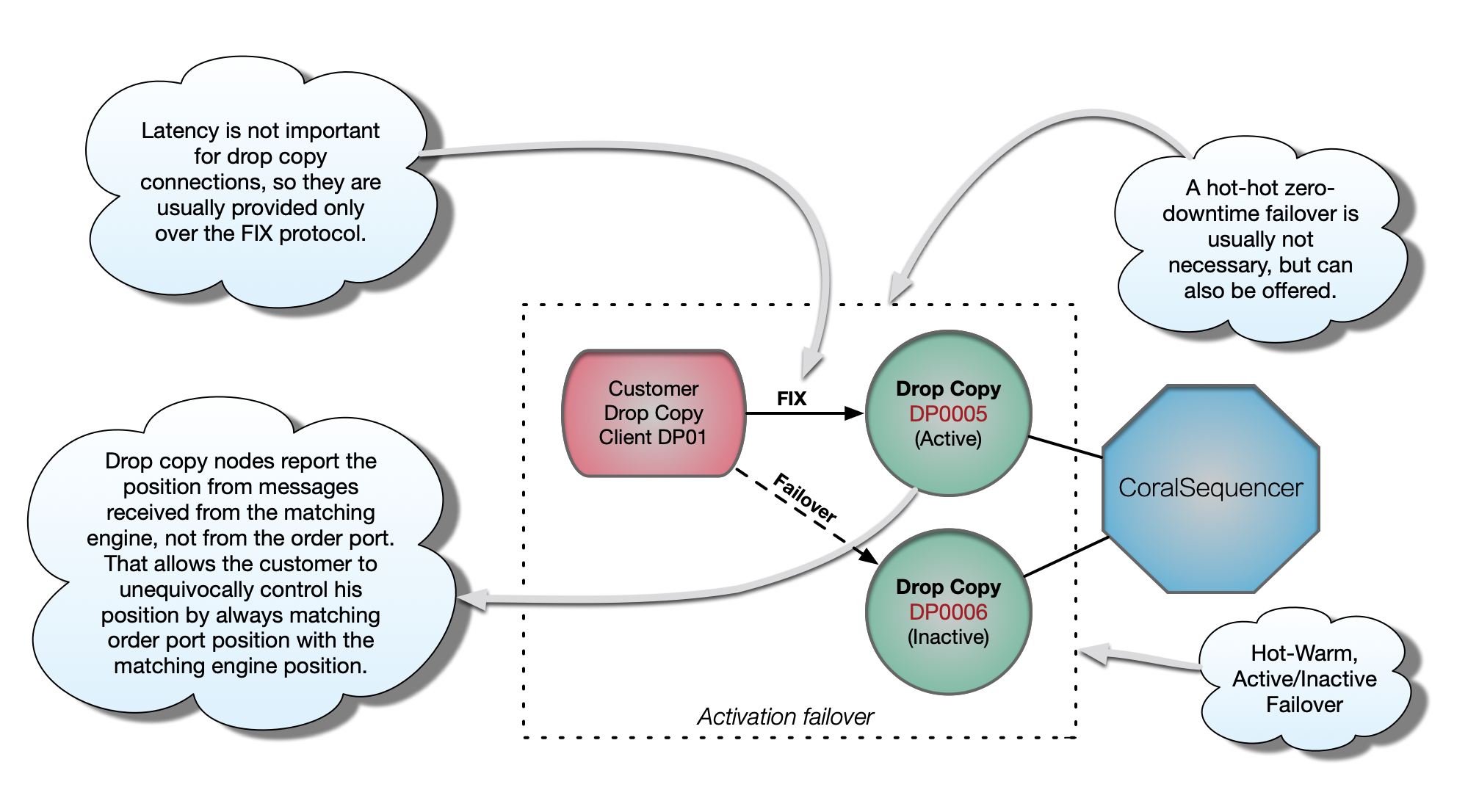
For an exchange customer to trust solely his gateways to be trading and maintaining a certain position can be very dangerous. It is always possible for a gateway bug to slip into production and create large losses without him even knowing about it. Therefore it is important to always match the position the gateway is reporting with the position that the drop copy is reporting. A mismatch there is a serious indication that something is very wrong and needs to be addressed by the exchange customer immediately.
And Much More
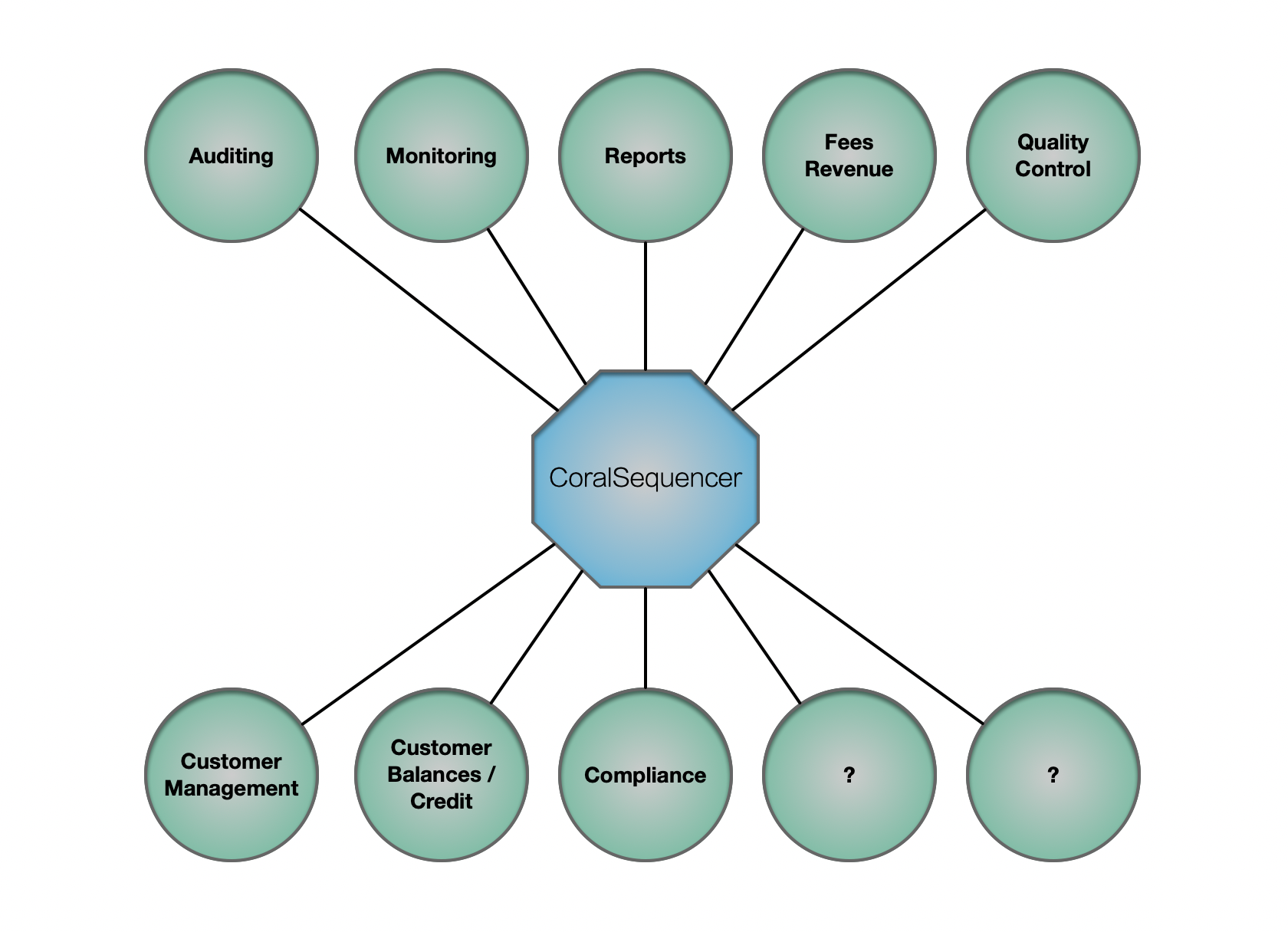
Because all CoralSequencer nodes see the exact same set of messages, in the exact same order, always, the exchange can keep evolving by adding more nodes to perform any sort of work/action/logic/control without disrupting any other part of the distributed system.
To summarize, CoralSequencer provides the following features which are critical for a first-class electronic exchange: parallelism (nodes can truly run in parallel); tight integration (all nodes see the same messages in the same order); decoupling (nodes can evolve independently); high-availability/failover (when a node fails, another one can be running and building state to take over immediately); scalability/load balancing (just add more nodes); elasticity (nodes can lag during activity peaks without affecting the system as a whole); and resiliency (nodes can fail / stop working without taking the whole system down).